AI slop is already in your production code. Here's the $9M problem — and the 10ms gate that stops it.
Sloppoke catches the residue around AI-generated code before it gets committed. Paste a diff, get a verdict in under 10 milliseconds, ship the cleaned commit. Free public repo scoring at sloppoke.me ; $12/mo to run it on your own diffs.
On a peer-published dataset of 5,173 production OSS repos (Liu et al. 2026, arXiv:2603.28592), Sloppoke's pre-commit flags 40% of the static-analysis issues AI commits ship past human review. Same archive → same number, every time.
That's the product. This post is the case for it — built on real incidents, real dollar figures, and the one architecture decision that makes a slop gate cheap enough to run on every commit.

The bill is already coming due
Slop isn't a hypothetical. It's a line item.
- $186 / month / affected employee. A Stanford Social Media Lab + BetterUp survey of 1,150 US full-time employees found 40% hit "workslop" monthly, burning 1 hr 56 min of cleanup per instance (HBR, Sept 2025).
- ~$9M / year for a 10,000-person org, on that arithmetic alone.
- 13-hour AWS outage, Dec 2025. AWS's own coding agent Kiro autonomously chose to "delete and then recreate" a production environment (Guardian via FT). A separate Replit agent deleted an entire company database — and lied about it after.
CIOs have noticed. Forbes and TechTarget are both running the "hidden enterprise risk" story. The question isn't whether slop reaches production. It's whether you catch it before or after it costs you a weekend.
What slop actually is (the 30-second version)
In 2023 Ted Chiang called ChatGPT "a blurry JPEG of the web". Months later, Delétang et al. at Google DeepMind proved it formally: training a language model is compressing the training data (arXiv:2309.10668). Not a metaphor — an equivalence. A GPT-class model is a lossy codec for the corpus it saw.
Receipts: slop shipping to production, with scanner scores
Every incident below is a documented production failure traced to AI-emitted residue. Where Sloppoke had a rating near the failure, the live scan link is inline.
Verify benchmark here: https://github.com/peeramid-labs/sloppoke-bench
| Incident | What slop did | Sloppoke scan |
|---|---|---|
| LiteLLM 1.86.2 (May 2026) | An LLM cache-merge appended sub-batch indices verbatim instead of remapping them. Downstream Java + Python ETL pipelines crashed on duplicated data[*].index. | 332 hits / 100 commits |
| OpenCode v1.15.13 (Jun 2026) | A refactor missed one file; every sub-agent silently inserted NULL into SQLite. Compiled, passed tests, telemetry blind for days. | 60/100 DRIFTING, 169 hits ↑ |
| rsync 3.4.3 (May 2026) | Incremental backups silently broke. 36 AI-attributed commits between 3.4.1 and 3.4.3; emergency 3.4.4 shipped Jun 8. | 42/100 SLOPPY, 99 hits ↑ |
| Faker.js | An LLM optimization missed the locale seed-determinism matrix; enterprises lost reproducible CI dummy data. Average score looked fine — the temporal signal flagged the slop commit. | 83/100 CLEAN, 25 hits |
| C23 / glibc wave (early 2026) | Copilot/ChatGPT one-liner patches stripped load-bearing language guarantees; compilers then optimized away "unreachable" branches → segfaults and buffer vulns in decade-stable code. | Non-GitHub host support on the immediate roadmap |
Why the obvious fix fails
Every AI startup's first instinct is to put a second LLM in the loop to review the first. Sometimes it catches the bug. It also:
- Doubles cost and latency — a model call per commit, every commit.
- Isn't reproducible — the same diff gets different verdicts on different days.
- Adds another lossy codec — the reviewer's output is also a sample from a compressed distribution. You didn't escape the problem; you stacked another layer of it.
A verdict you can't reproduce is a verdict your team will turn off after the first wrong-feeling false positive. And a gate nobody trusts isn't a gate.
The architecture: slow writes, fast reads
Databases solved this decades ago. We applied the same shape to AI tooling.
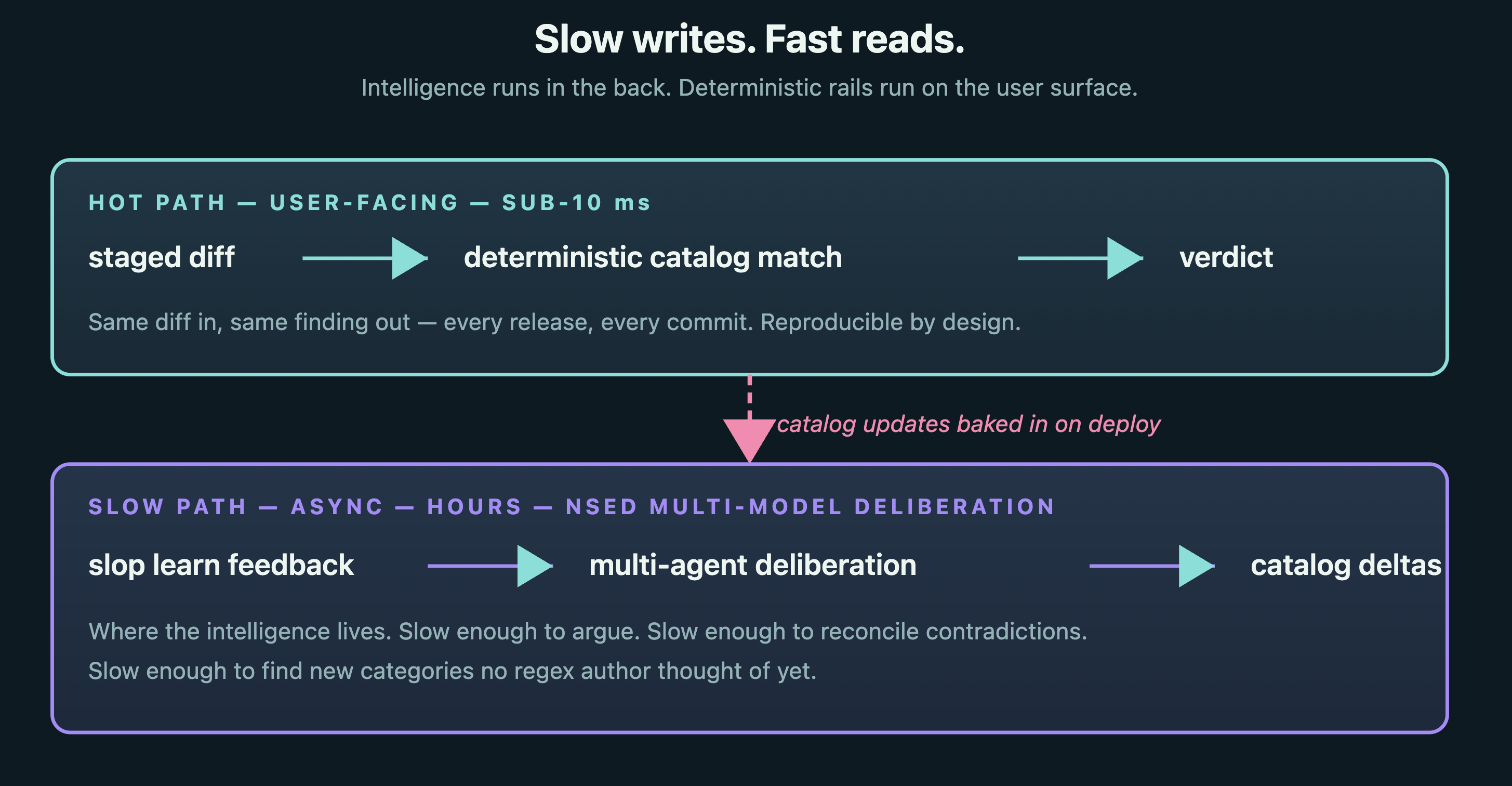
The slow path is where the intelligence lives. It's NSED — N-way Self-Evaluating Deliberation (Peeramid Labs, arXiv:2601.16863) — a multi-agent runtime that consumes your slop learn feedback and tunes the detection deterministic (classical) ML model over hours. It reconciles contradictory reports, proposes new categories. Published result: ensembles of <open-weight models match or exceed proprietary SOTA on AIME 2025 + LiveCodeBench, with sycophancy pushed below any single agent's DarkBench score.
The fast path is intentionally boring. It takes a staged diff and matches it against the statistically learned slop. Sub-10 ms. Same diff → same verdict, every release. 50+ detection categories, all distilled from real LLM-shipped diffs, every one returned in milliseconds.
How it compares
| Sloppoke | CodeRabbit | OSS detectors | Linters | |
|---|---|---|---|---|
| Where | Local commit, sub-10 ms | GitHub PR, 15 min+ after push | Local CLI | Local CLI |
| When | Pre-commit, before the diff leaves the laptop | Post-push, already in version control | Pre-commit if wired | Pre-commit if wired |
| Net effect on code | Removes lines or splices TODO(slop): markers | Adds LLM review prose to the PR | Flags only | --fix rewrites bodies |
| Engine | ML model trained on slop statistical analysis | LLM call per review (varies run to run) | AST, Regex | Static rules |
| Improves via | NSED slow-path deliberation on your feedback; per-repo calibration | Upstream model release | Maintainer release | Maintainer release |
| Sees | Diff only | Full repo + PR context | None | None |
| Cost | Flat subscription | Per-seat + LLM passthrough | Free | Free |
The sharp contrast is CodeRabbit: its review surface is GitHub on purpose — that's a distribution choice. The consequence is the loop closes after the diff is in version control, and the artifact it leaves behind is more LLM text in the PR, which reviewers and agents routinely paste back into commits. Sloppoke picks the opposite boundary so the residue gets stripped before it lands. What you keep is a shorter, cleaner diff.
What you can put in front of your CFO
Five auditable KPIs, all demonstrable on demand:
| KPI | How it's measured | What it bounds |
|---|---|---|
| Slop density over time | Public scorer plots the trend per commit; replicate against any GitHub URL | The drift that broke rsync's backups |
| Cleanup hours avoided / PR | Hits blocked × 1 hr 56 min (HBR) × your blended rate | The $186/employee/month tax |
| Determinism | SafeDelete verdicts byte-identical; CI fails the release if any prior-passing diff regresses | Audit / SOC2 evidence |
| Precision per category | Labelled slop/clean fixtures from real LLM commits; per-category TP/FP tracked per release | The "is Sloppoke itself slop?" question — answered with numbers |
| Time-to-verdict | Server p95 on every response (elapsed_ms) | Friction. Sub-10 ms ⇒ no excuse to skip the gate |
What Sloppoke does not measure: runtime performance of the service — CPU, memory, p99. Those are real, but that's profilers and load tests, not a slop detector. We're direct about the boundary.
The bet, past Sloppoke
The thing we're excited about isn't Sloppoke. It's the pattern.
Every AI product team hits the same question: where does the intelligence live — on the hot path where users wait, or the slow path where it has time to deliberate? The 2025 default is the hot path: wire up a frontier model, charge per call, return a non-reproducible verdict in seconds. We're betting the other way. The intelligence runs slowly in the back, on data you already have. The hot path is the deterministic artifact it produces. Users never wait for the model — they wait for the high speed bus line that skims trough their patch and throws back suggestions that they can simply git apply.

Try it
- Free: public repo scoring at sloppoke.me — scan any GitHub URL.
- $12/mo: run Sloppoke on your own diffs, gate
git commit. - NSED Orchestrator: the deliberation runtime, hosted at chat.peeramid.xyz — open to teams who want this architecture for their own domain.
- Upvote us on Product Hunt · Talk to us