Misty Future of The Cloud
Cloud computing has been a major industry solution for many many years by now, enabling users, greatly reducing friction of using any software or tool.
Thanks to the IP and advancement in telecommunication networks it became feasable to pull huge amount of data into the cloud, which evolved to what we largely know today as Cloud computing and Software-as-a-Service.
However, this trend is changing. Industry is not stagnant and regulations, opportunities, hardware, devices, advancements in the protocols and software keep on pushing us to the limit. In this article, let's dive in and see why we believe that future of the cloud is misty.
Why did Cloud thesis succeed?
Traditional answer to this question of success of the cloud is that it greatly reduced complexity for the end-users, allowing services to be abstracted away from the tenants using them.
However, if we take a deeper look into the cloud thesis, in general telecommunication networking stack, particularly the OSI model, then we can spot that user-software distribution is only a part of the answer.
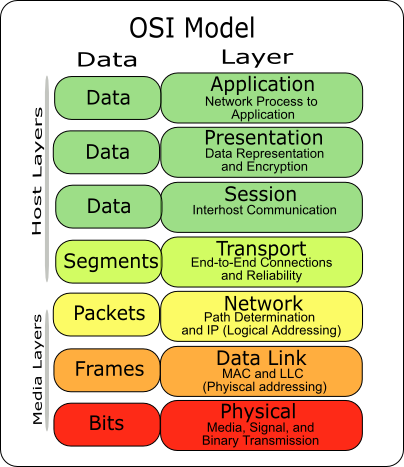
There is another deeper fundamental issue. Even if there would be great devoted people trying to solve the complexity to the end-user software distribution, it would still be prohibitively complex for natively running applications on the edge for user devices.
That particular challenge - is current IPv4 and IPv6 are fundamentally made in "star" topology, while alternatives back in the date when IPv4 was formalised existed, it allegedly won due to its simplicity and network maturity by that time. It is important to understand that IPv4 was introduced in 1980!
Thus, all that immerse infrastructure that we have built up to the day, in fact stands on 46 years old protocol shoulders, that haven't been changed except with a "minor" bump to ipv6 which did not change much enough and still today is not widely adpoted.
Smart reader can notice a tree / star pattern of Internet from the Internet snapshot of year 2005.
How IPv4 packets know "where to go"?
TLDR: they don't, they are just being sent upstream. In Internet traffic everything happens in packets every packet has payload and header. In fact, you may think of internet as post infrastructure.
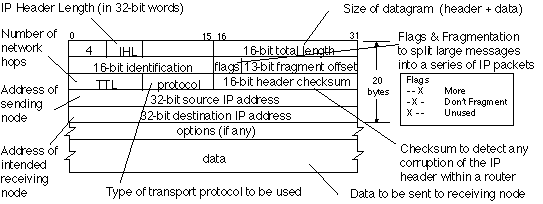
User has an envelope (header) and a letter (message) inside. IPv4 header has maximum 60 bytes length, in which destination, origin, and everything relevant to packet journey must fit it.
When you connect to a cloud, your packet journey until the "envelope" is opened can be dozens of devices - wifi routers, switches, baseband stations. They all add up quickly. Headers cannot list all of the hops at the "envelope" header beforehand.
Instead, a patch called Border Gateway Protocol (BGP) is invented. Upstream devices literally shout "I know closest path to Bob", your device trusts them implicitly, and sends to whomever claims to know shortest path.
Network addresses in its turn are always issued by the upstream, thus ability to actually reach someone by design is centrally controlled that first upstream node that owns both sender and receiver.
It is important to understand nuanced terminology:
control plane - "I own router, my network = my rules"
data plane - "If you want to send file from Bob to Alice on my network, here is where it goes"
In a traditional IP router, the control plane (which decides routes) and the data plane (which forwards packets) both run on the same device, but they are logically distinct.
traditional IP routing style: "I own your network, so send all data to me, and I promise to forward it."
This approach has so many downsides. I will not be able to list all 46 years of patches around without collapsable accordion:
Abyss of ipv4 patching
Routing & Path Management
- MPLS & RSVP-TE
- Why: To force traffic down specific physical cables (traffic engineering) instead of relying on unpredictable standard routing.
- Why it's bad: Requires massive state synchronization across all routers; fragile and slow to recover when hardware fails.
- RPKI & ASPA
- Why: To stop attackers from announcing fake BGP routes and hijacking traffic.
- Why it's bad: Relies on centralized authorities and doesn't mathematically guarantee the actual physical path the packets take.
- Policy-Based Routing (PBR) & VRFs
- Why: To force packets to detour through specific firewalls or scanners (service chaining).
- Why it's bad: Requires highly manual, rigid, and fragile configuration at every single network hop.
Identity & Security
- IP Access Control Lists (ACLs) & IP Whitelisting
- Why: To block malicious actors or allow admins based on their IP address.
- Why it's bad: IP addresses are easily spoofed, constantly change, and do not represent actual cryptographic identity.
- IPsec & Overlay VPNs
- Why: To build private, encrypted tunnels over a hostile public internet.
- Why it's bad: Computationally heavy, breaks easily behind firewalls, and requires slow connection handshakes before data flows.
- What: Deep Packet Inspection (DPI)
- Why: To inspect payloads to identify applications for traffic prioritization or blocking.
- Why it's bad: Invades privacy, requires massive processing power, and is completely blinded by modern end-to-end encryption.
- Bastion Hosts (Jump Boxes)
- Why: To hide internal network infrastructure behind a single, heavily guarded entry point for remote administration.
- Why it's bad: Creates a high-value target and a single point of failure; if compromised, the whole network falls.
Device & Hardware Management
- SSH & Local OS Daemons
- Why: To securely access a remote device's command line to configure, reboot, or troubleshoot it.
- Why it's bad: Forces every piece of hardware to run a bloated operating system (like Linux) and a listening daemon, creating massive compute overhead and an enormous software attack surface just to execute basic hardware commands.
Peer-to-Peer & Connectivity
- NAT & CGNAT
- Why: To share limited IPv4 addresses among multiple devices.
- Why it's bad: Destroys fundamental end-to-end connectivity, permanently hiding edge devices behind routing layers.
- STUN, TURN, & ICE
- Why: To punch holes through NAT firewalls so peer-to-peer applications can communicate directly.
- Why it's bad: Hacky, unreliable workarounds that frequently fail, forcing traffic back through centralized relay servers.
- Layer 7 ZTNA (Software Overlays)
- Why: To hide open ports and securely connect remote devices via third-party software meshes.
- Why it's bad: Requires installing proprietary agents on every device; destination servers still waste CPU processing and dropping hostile packets.
Most notable in this list that lead for Cloud service model are
- Centralised "star" Topology itself: In ipv4 paradigm data always first flows to upstream controller. It is natural cloud direction, thats why IoT edge largely had to invent own protocols such as BTMesh, .
- NATs / Static IPs: Your phone has no immutable IP address on the network. It is ever changing (dynamic), and usually costs extra premium to purchase a static IP that your internet provider promises to forward packets to you.
First makes Cloud natural - data already flows in to central aggregator by design. Second makes Edge complex - can only provision static IP from his provider and needs technical expertise to setup equipment work with that. Switch on to Starbucks WiFi - it's all gone, you are behind NATs and your counterparty does not know your actual IP to talk directly.
How about IPv6?
You might have heard of IPv6 as it is being sold as "fix for the internet" for past decade or so.
Fundamentally it still is same star topology. It does address some of the issues, however the lack of adaption on it is directly sequence of being only marginal improvement.
As AI demands massive data movement and regulations demand data sovereignty, the old 'Star' model isn't just sub-optimal—it's a liability. This is why the industry is moving.
Misty future
Mist is a term sometimes used to describe data processing on the edge, distributed from the cloud, operated by telecom operators or similar entities.
Making all data travel upstream is often sub-optimal, lack of network management policies in programmable way creates massive industry overhead and ever lasting vulnerabilities that never will be ever patched completely. If all data has to flow to upstream, this is a single point of failure in the network. These are very basic problems.
These are just technical problems, but there are also legal/business point:
- Centralised data-center solutions often struggle with data privacy compliance, especially in cross-jurisdiction cases. With rapid scaling of AI the data sovereignty has crucial importance.
- There is long lasting demand for direct peer-to-peer content addressing. Blockchain industry can be largely seen as this demand materialised - for financial operations you want account based addressing.
New standards already being rolled out
Currently Tier1 and Tier2 ISPs are actively rolling out SRv6 technology, western vendors like Cisco are positioning it as network for age of AI and Eastern players like Huawei both support SRv6, standardised by the IETF (RFC 8754, RFC 8986). APN6 (Application‑aware IPv6 Networking) is an IETF‑track extension that adds application‑layer awareness on top of SRv6. Huawei implements both.
Major carriers are already running SRv6 at scale. China Mobile’s 5G backbone uses SRv6 across more than 300,000 devices, and Reliance Jio in India has built one of the world’s largest SRv6‑native networks. These are not lab trials but live, revenue‑carrying networks.
Both fundamentally are doing same thing: take existing IPv6 standard and extend it with instructions directly attached to the envelope. Think of these as “postal instructions” added to the outside of the envelope. The envelope (IPv6 header) still shows the destination, but a separate Segment Routing Header (SRH) lists the exact intermediate post offices the letter must visit. An APN6 extension can further declare the application type for quality‑of‑service handling, all without altering the original address.
These are embodiment of concepts of Software-defined Networking (SDN). This allows one controller to programmatically steer fleet of telecommunication devices. System administrators won't need to log in to devices via ssh to configure them anymore. Even more - they might well not need Linux on most of their equipment at all due to that.
SRv6 closes one Cloud moat, keeps second:
- Mesh data topology: While control planes stay centralised by network equipment owners, the data flows now support direct peering
- Cryptographic addressing: This still is a challenge. SRv6 still relies on IPv6, where, at best, you can get a Cryptographically Generated Address (CGA) with 112 bits of security (using the maximum sec=7 parameter). An Ethereum address is a 160‑bit hash of a 256‑bit public key, providing 128 bits of classical security. Neither a 160‑bit identity nor a 256‑bit post‑quantum public key fits directly into the 128‑bit IPv6 address field.
SRv6 still cannot route address by identity:
You might wonder, why after seeing that IPv6 adaption largely failed, industry tries yet-again to patch, issuing SRv6 which still does not address all of actual consumer needs?
The reason is huge inertia in telecommunication industry. Most of telecom chips manufactured over past 25 years are physically etched to work on 128-bit address registries.
They simply cannot fit in 160-bit security required for Ethereum today, not even mentioning Post-Quantum cryptography needs.
Anything that changes this paradigm will automatically trigger multi-billion dollar upgrade worldwide, with some of equipment literally buried in the ocean depths.
The industry's solution, as explored in the SRv6/APN6 model, is not to make a bigger address. It's to decouple identity from the address entirely. Your 128-bit IP address continues to be a dynamic, location-based routing tag. Your persistent, 160-bit cryptographic identity becomes a separate, verifiable piece of metadata in the packet's Extension Header.
ITU-T New IP / Xinghe Intelligent Network
Also known as IPv6+, this is much larger, state baked upgrade, pioneered by Greater China and Huawei.
The original “New IP” proposal included variable‑length addresses, but this was abandoned after intense industry pushback. The current IPv6+/Xinghe architecture keeps the standard 128‑bit IPv6 address. Instead, it places cryptographic identities and application metadata in programmable Extension Headers (APN6). This decouples the “where” (the IP address) from the “who” (a persistent, verifiable identity), effectively making Web3 identities first‑class citizens at the network layer without changing the address length.
Having account identifiers in the network packet level is a large privacy and censorship concern, however it is exactly what makes network efficient. Privacy can be addressed with Zero-Knowledge identities, keeping best of both.
Maybe that's why in February 2026, China successfully spearheaded and published the world's first international standard for zero-knowledge proofs.
ISO/IEC 27565:202 titled "Information Security, Cybersecurity and Privacy Protection — Guidelines on Privacy Preservation Based on Zero-Knowledge Proofs." Published in February 2026, this is the first international standard providing guidance on how ZKPs can be used for identity verification and compliance without disclosing underlying personal data.
The "New IP" initiative itself was brought up as ITU-T New IP standard, avoiding being blocked in largely failed IETF / IEEE circles.
The original 'New IP' proposal's most radical feature was variable-length addressing, allowing for much longer cryptographic keys directly in the address. This was seen as a 'red line' by the IETF, as it would create an entirely new, incompatible network layer.
European Telecommunications Network Operators' Association largely rejected it with following claims:
- Large investments required to upgrade whole network
- seen conflicting ITU vs IETF/IEEE - who is owning standards
The backlash led to the current 'IPv6+' strategy, which keeps the 128-bit address but achieves its goals by using programmable Extension Headers. The vision didn't die; it was tactically reshaped to fit the existing physical hardware.
Today "New IP" is not a clearly protocolled standard that we can refer with conventional RFCs, but rather a business solution that is implemented as Xinghe Intelligent Network.
We can only hope for more transparency and over the time RFC standards of IETF as this is clearly important for global interoperability.
Bottom line
The very foundation that drove cloud success is changing over next decade.
The industry’s chosen path is to keep the 128‑bit IPv6 address and make identity a header property, not an address field
Mesh based data addressing is already closing in, and as initiatives like IPv6+ are ramping up, we are likely to witness more and more telecommunication equipment upgraded to support SRv6‑based, identity‑aware networking, where persistent, cryptographically‑verifiable identities are carried in extension headers, enabling direct peer‑to‑peer communication without a central cloud hub. This transition will probably take 5‑15 years, driven by the same infrastructure inertia that slowed IPv6 adoption.