NSED v0.5.1: Don't Trust Your Agents. Verify Them.
v0.5.1 Release Announcement
Multi-agent deliberation is only as good as the operator's ability to intervene when it matters. NSED v0.5.0 with 0.5.1 patch ship the infrastructure to make that possible at scale: a full Human-in-the-Loop (HITL) control plane that puts enterprise operators back in command of their agent fleets — without sacrificing the throughput that makes automated deliberation worth running in the first place.
TL;DR
- Orchestrator User Interface — create and follow the deliberation process, inject orchestrator messages to steer the discussion and export audit trace JSON.
- HITL Control Plane — pause agents, review and edit buffered responses before they reach the orchestrator, apply live config patches, and auto-flag underperforming agents, all from a new operator dashboard
- Embedded NATS + multi-arch Docker — single
docker runstarts the full stack on amd64 or arm64; CI builds complete in under two minutes - Zero-config bootstrap via
nsed-orchestrator init— interactive setup wizard discovers local models, writesdocker-compose.yml+.env, and gets you to a running deliberation in minutes - 40+ bug fixes including a critical scoring defect that could cause an unevaluated proposal to win as "best"
- 300+ new test functions across all crates
⭐ star the repo → github.com/peeramid-labs/nsed
For a full compliance suite feature see our compliance page: https://peeramid.xyz/compliance/
NSED recap VS other frameworks
Before diving in, a quick recap of how NSED works.
NSED's deliberation protocol — N agents proposing, cross-evaluating, and converging — produces reasoning quality that exceeds single-model inference. The AIME 2025 benchmark results (arXiv 2601.16863) make that case in numbers. But what matters even most, is that NSED allows address key UX challenges LLMs and tech industry faces.
Problem today with AI solutions
Today agent solutions are highly manual. AI suffers from hallucinations mostly because context is either missing, either is lost in the middle. Real human collective has large amount of shared knowledge & knowledge exchange - a sync checkpoints AI has not.
This leads to chaos, manual complexity and overall difficulties later on to explain how exactly initial business requirements were linked by prompts and checks to the outcomes.
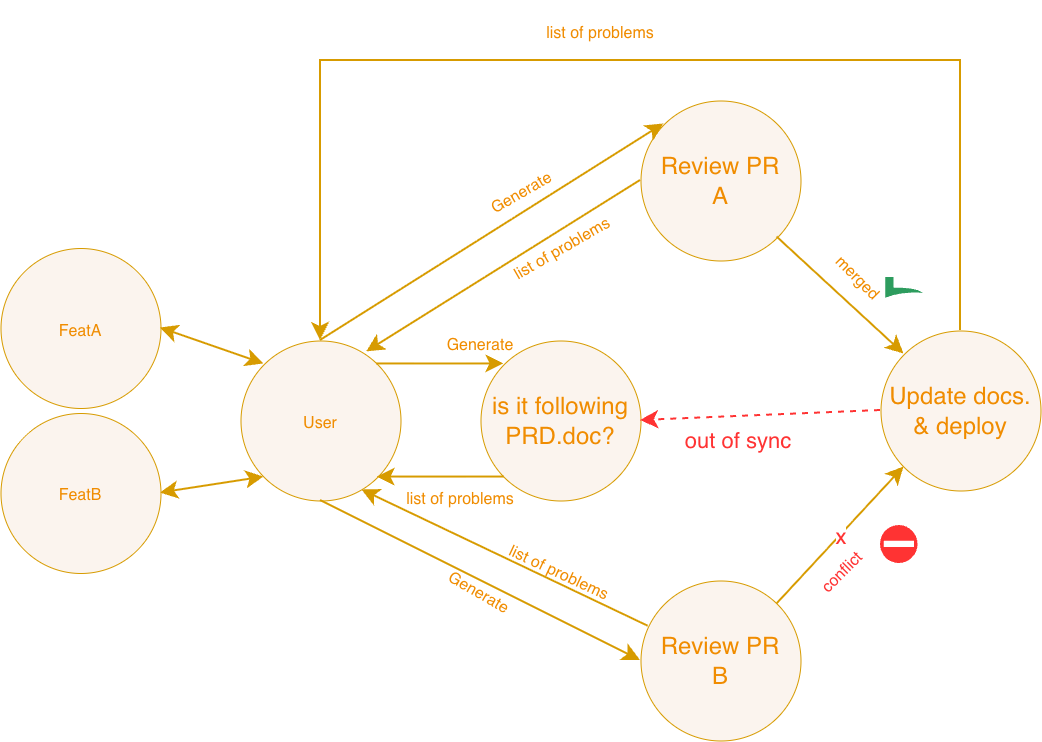
Built to make a difference
NSED is a first of a kind parallel agent framework. It does not require you to have a central AI agent, thus it enables higher-abstraction reasoning trough convergence of multiple models/agents over their own context and own work towards the outcome. It brings less hallucinations and faster time-to-results.
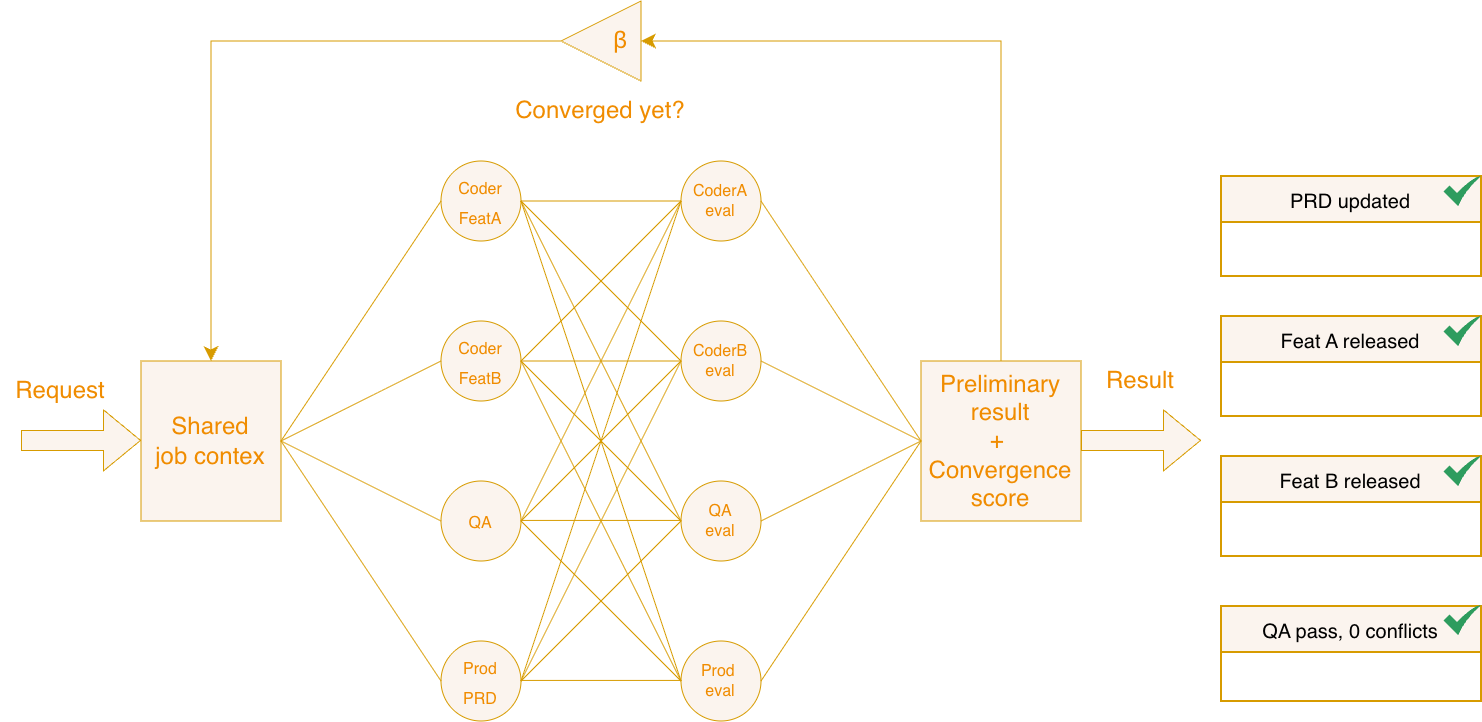
You may think of it as of
"GPU of agentic AI workflows"
Why Human-In-The-Loop?
The MAS AIRM Guidelines, EU AI Act Article 14, and FINRA 2026 all converge on the same requirement: high-stakes AI systems must support meaningful human oversight, not just nominal audit trails. "Meaningful" means operators can see what agents are doing, intervene before outputs are committed, and demonstrate that intervention capability to regulators on demand.
v0.5.1 is the architectural answer to that requirement. It transforms NSED from a headless orchestrator — powerful but opaque from the outside — into a control plane that enterprise operators can actually manage.
One point worth making explicit for procurement and compliance teams: NSED is source-available under BSL 1.1. That means your team can read and audit the HITL mechanism implementation directly — the buffer logic, the annotation pipeline, the scoring thresholds — without signing an NDA or trusting vendor documentation. When a regulator asks how your human oversight works, you can show them the code, not a marketing diagram.
Get in touch — we'll walk through how NSED maps to your specific audit requirements.
How we make HITL work?
Human in the loop control works natively in NSED. This is not a wrapper, nor is a plugin - it is baked in the orchestration framework core protocol.
When content generation initiation happens, the system requires explicit SLA setup. This SLA sets timing constraints. For example you may want to have answer in 15 minutes, or by Monday morning. Further, SLA defines what kinds of expertise or data context shards is needed.
When agent operator launches his workspace, he sets own SLA announced to downstream consumers. This includes an explicit minimum time-to-response for tasks assigned. This time includes LLM generation time, plus the HITL review steps.
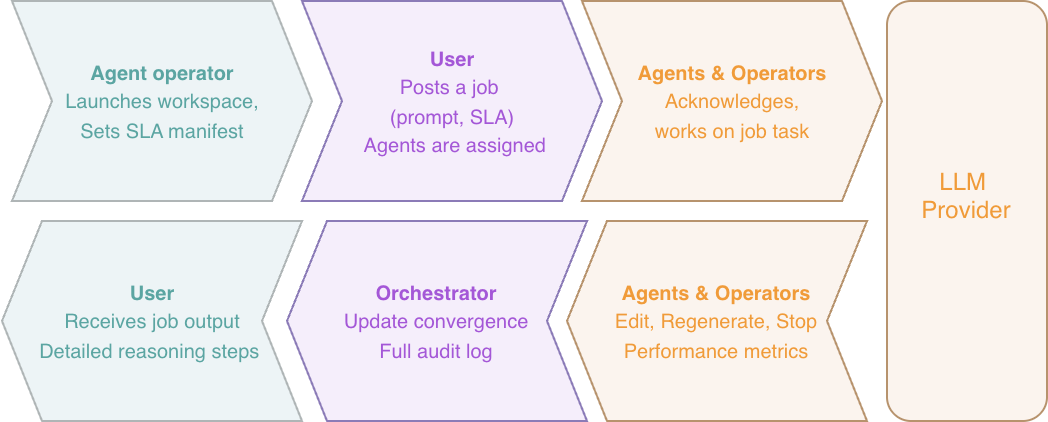
When user publishes job under SLA, this guarantees Just-In-Time delivery no matter what. The convergence metrics, full audit trace on reasoning, deliberation and operator interventions is stored.
The high level convergence metrics on each agent, allows operator to boost productivity, reviewing only flagged, problematic outputs, and our minimal interface already demonstrates that.
User Interfaces
The centerpiece of v0.5 is an operator dashboard API purpose-built for multi-agent fleet management. The built-in UI ships as zero-dependency vanilla JS — no npm graph, no webpack, no React.
In a control plane with pause/resume authority over live agent responses, that surface area matters: nothing a compromised package registry can silently inject.
1. Orchestrator UI
Orchestrator acts on user-proxy side job. It issues results full audit trace log and detailed telemetry. If agent disagree, you can see why, and track how they converge in integrating each other critiques.
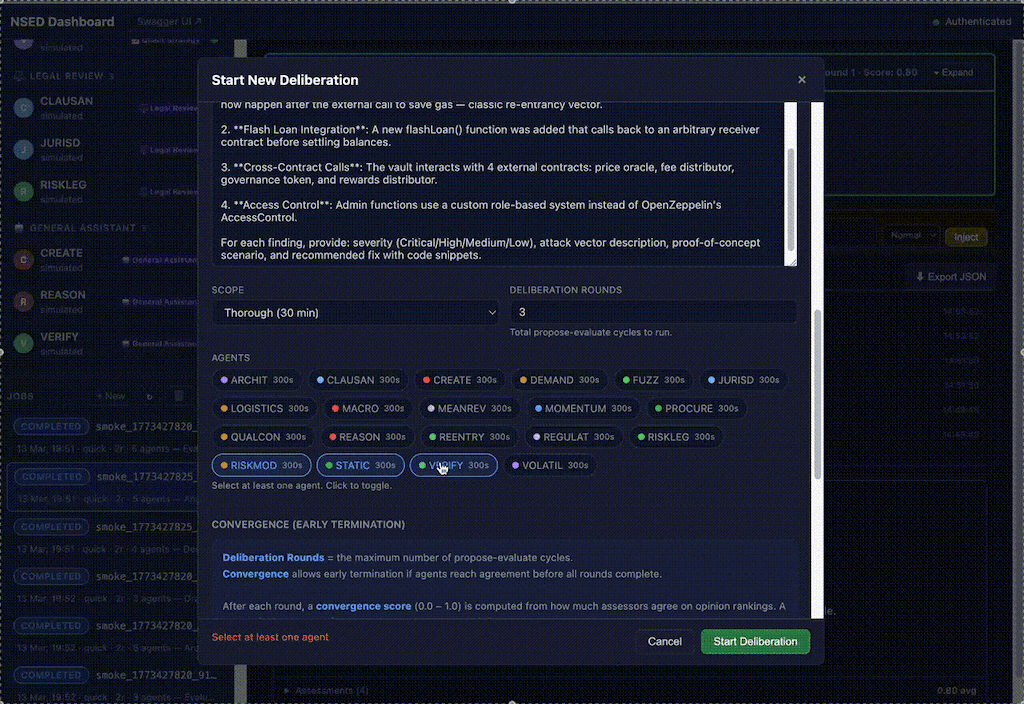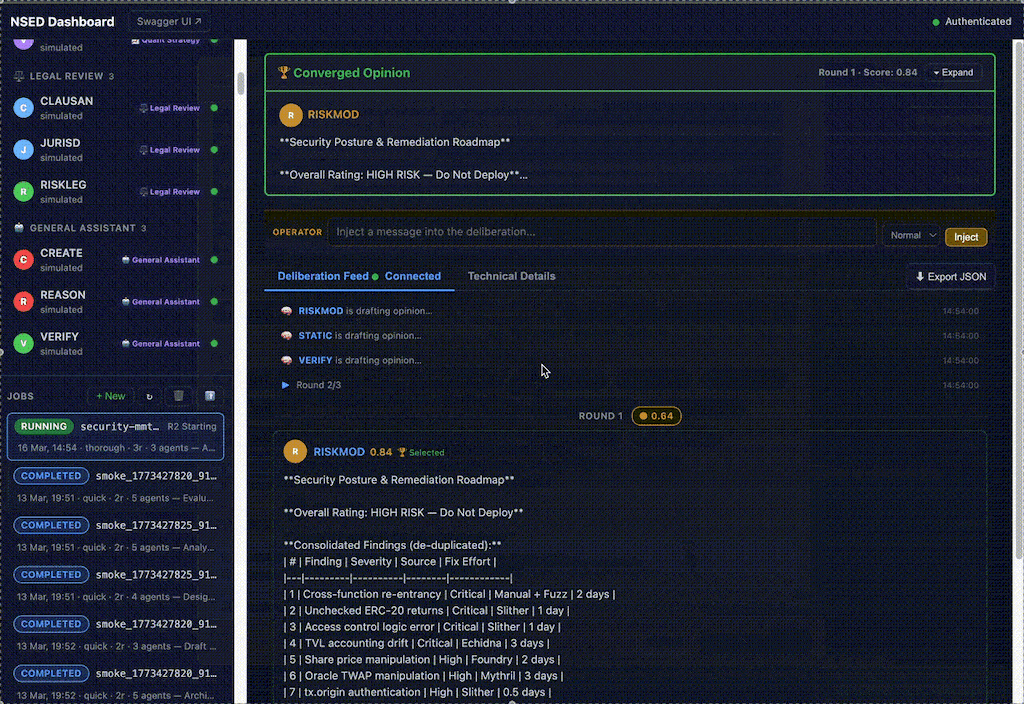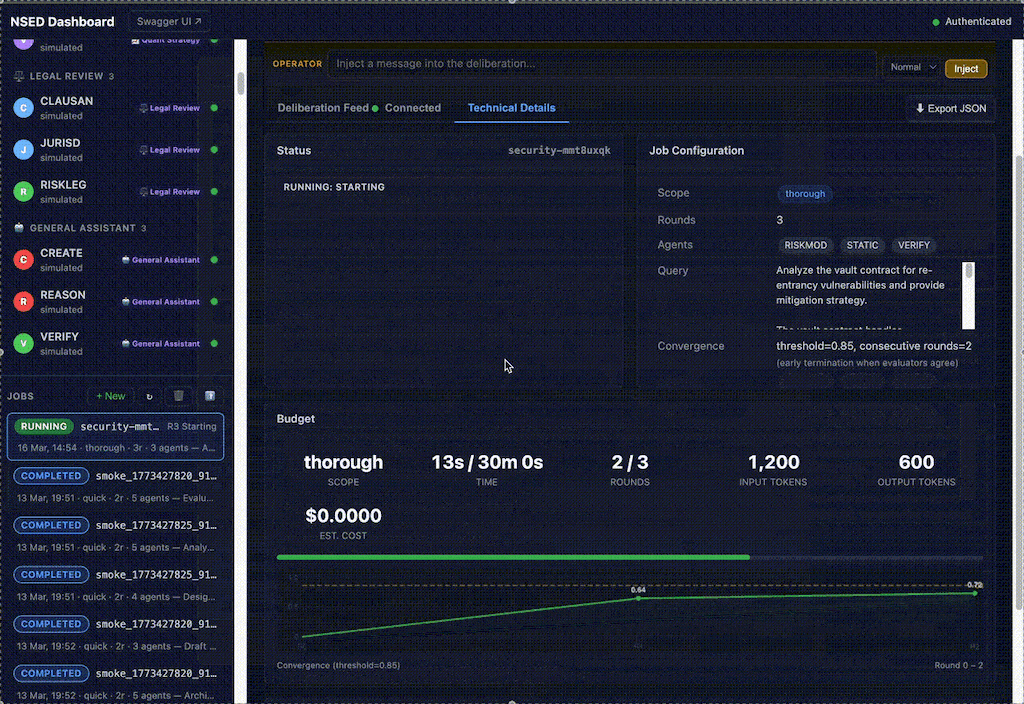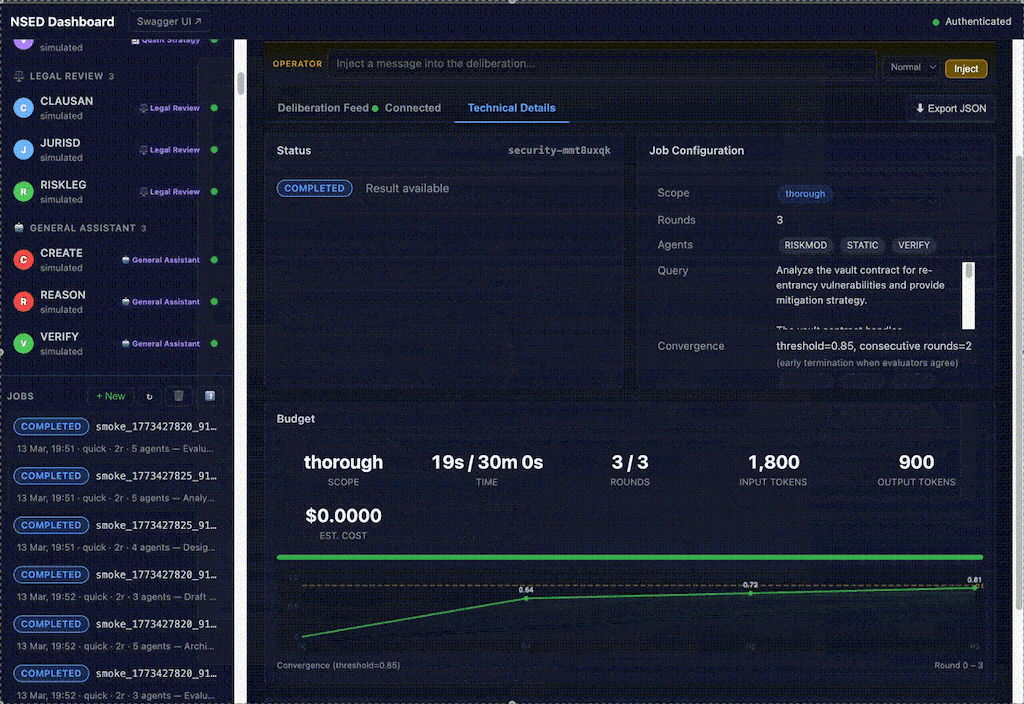
docker run ghcr.io/peeramid-labs/nsed:v0.5.1 You're two minutes from a running deliberation stack. nsed-orchestrator init handles the rest.Orchestrator has detailed view over deliberation process. For every round, detailed objections, evaluation critique appears, allows user and orchestrator operator to dig in, inject own corrections or completely kill-switch the job.
2. Agent Operator minimal UI
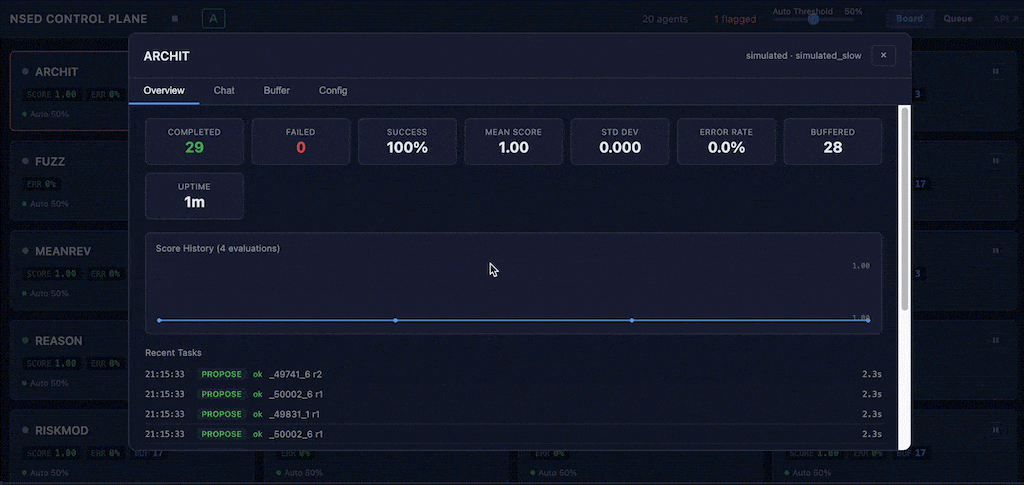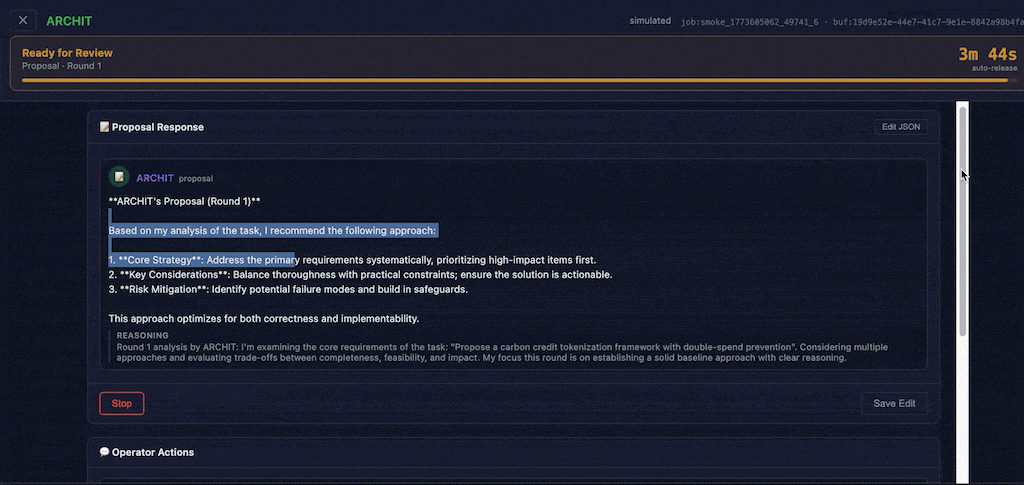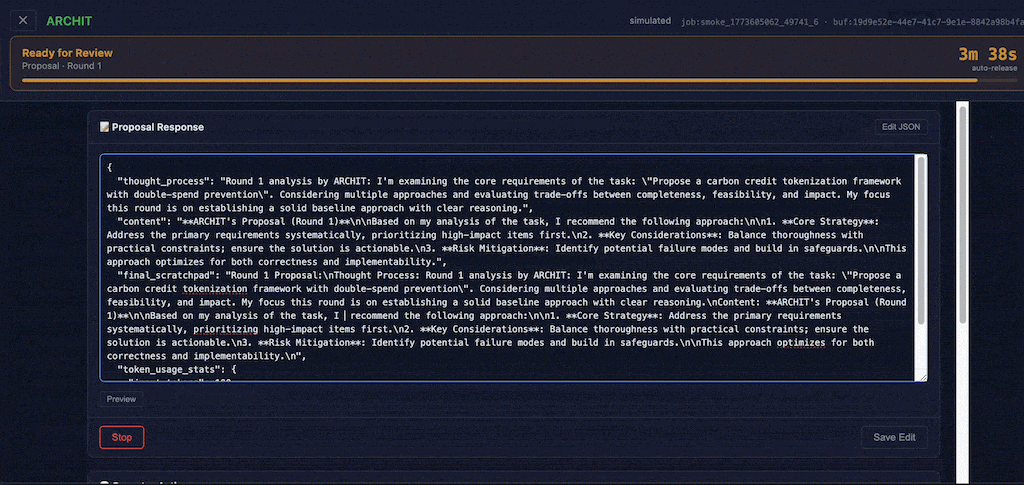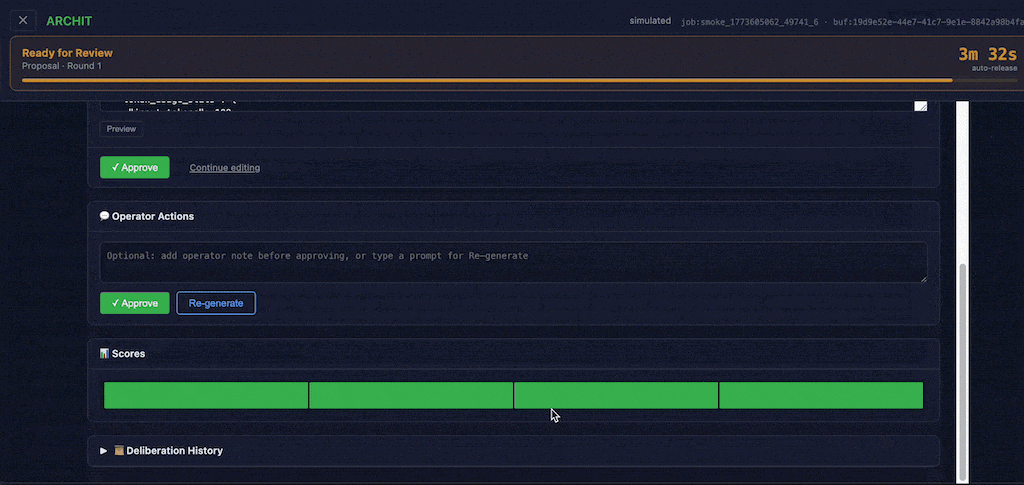
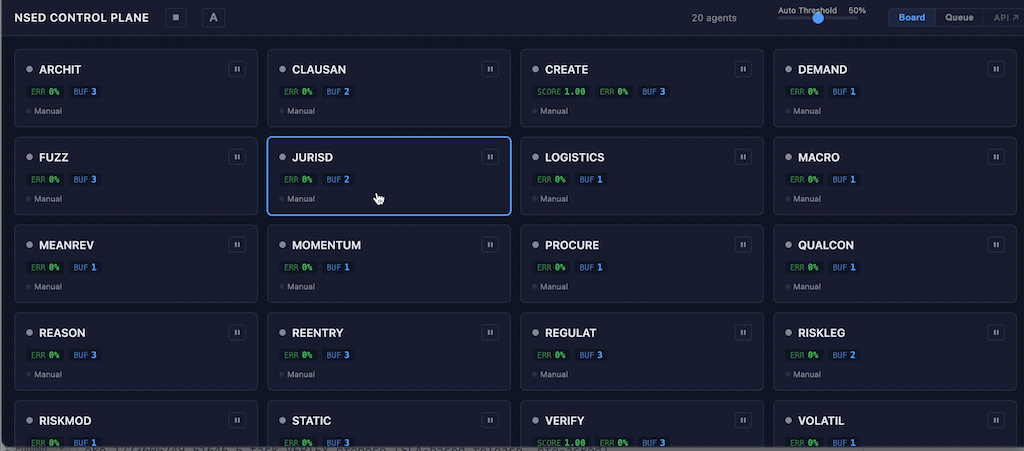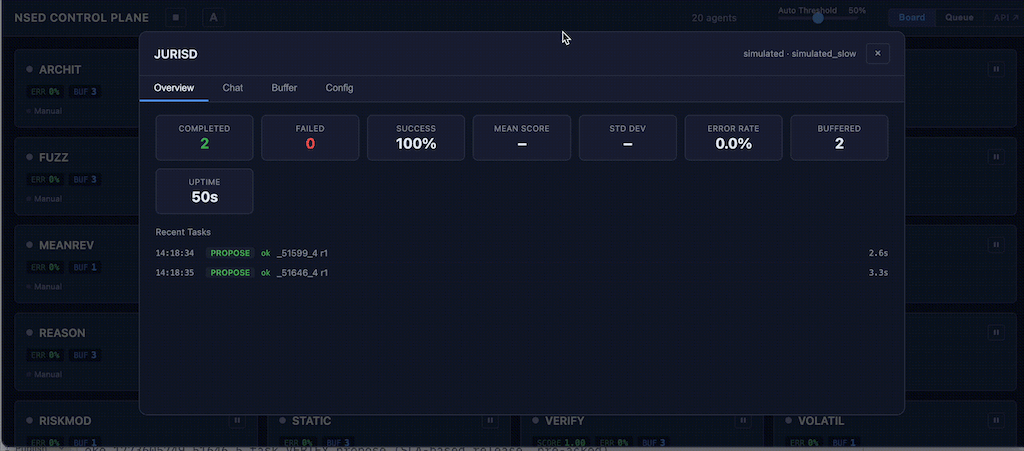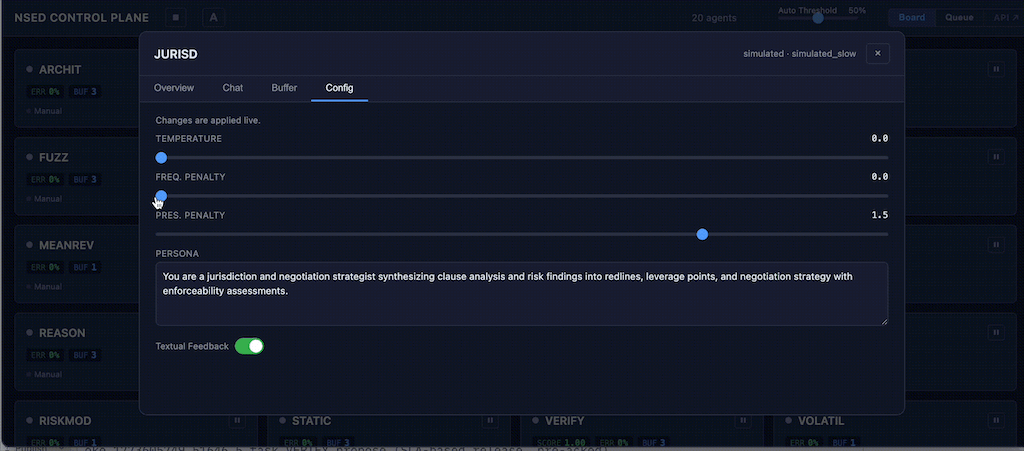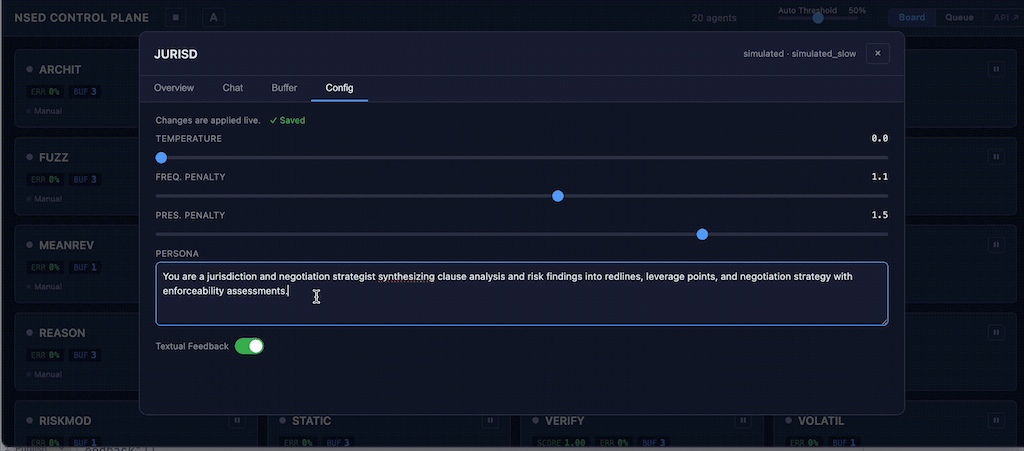
Board view renders each agent as an information-dense card in a responsive grid: live status, performance score badge, error rate, buffered response count, and pause/resume toggle. Operators see the health of their entire fleet at a glance.
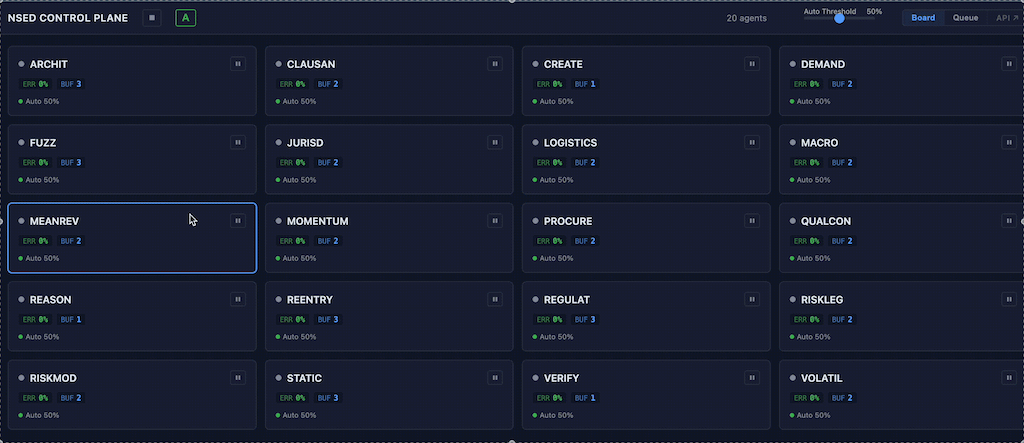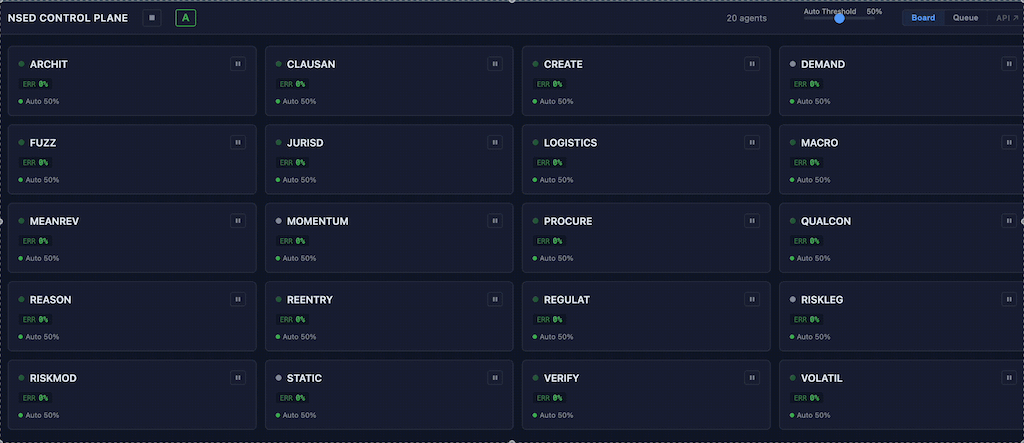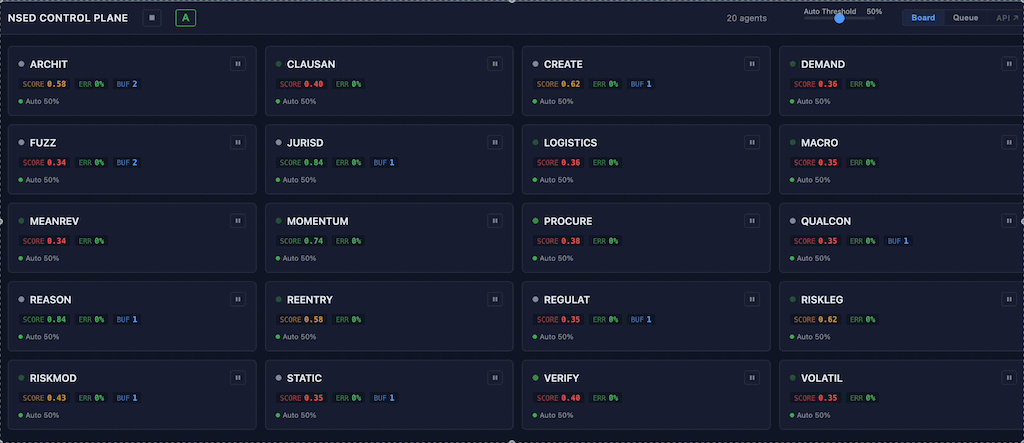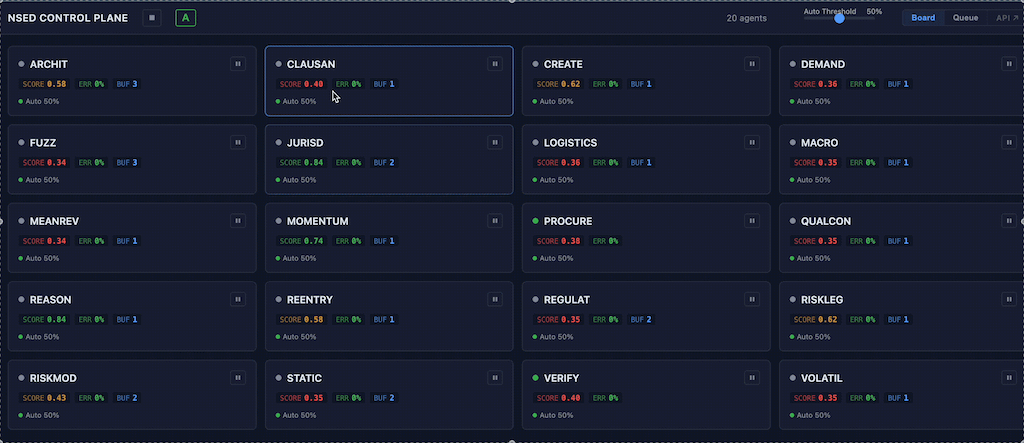
Task review is a key HITL operator control interface. It works for both proposal generation stage and evaluations. Clear time-left indicator allows operator to prioritise tasks. Operator actions are:
- Approve: Release generated content downstream.
- Re-generate: Instruct a LLM on what has to be fixed.
- Stop: Deny downstream response, leading to orchestrator-level escalation.
- Edit: Intervene and manually edit generated content.
- Add comment: Leave a message to rest of ensemble, side-channel visible to ensemble workers designated as agents operator.
Queue view is a unified, chronological work queue that surfaces every buffered response across all agents in a single table. Each entry shows agent name, action type, round number, job ID, how long it has been waiting, and an auto-release countdown. Inline actions — release, reject, stop, unstop — operate directly from the queue without navigating away.

Auto-staging
Based on our research and introduced evaluation metrics, we work on quantifying the hallucination probability via comparing convergence of different AI models & agents.
Staged generated content will be auto-released by the end of SLA and can be early-released if overall agent divergence is below set threshold.
This allows single operator to effectively operate dozens of agents simultaneously, relying on system metrics to flag what needs attention.
Agent detail modal opens a full-screen view with four tabs: Overview (performance stats, sparkline, task log), Chat (direct LLM conversation for diagnostic interrogation), Buffer (response list with inline edit), and Config (live sliders with debounced auto-save for temperature, penalties, persona, and iteration settings).
All views are backed by 16+ new REST endpoints covering pause/resume (individual and fleet-wide), config patch, buffer CRUD, chat, orchestrator registry, and global config management.
The multi-operator supervision architecture underlying this dashboard — bidirectional protocol mapping, entropy-triggered message staging, and per-operator visibility boundaries — is a patent-pending solution Peeramid Labs develops to bring the most secure and transparent world of Agentic AI.
Technical change list
1. ResponseBuffer: The SDK Primitive Behind HITL
For agent developers, the HITL control plane is exposed through the ResponseBuffer SDK type. Before a completed response reaches the orchestrator's JetStream, it lands in the buffer — held in a pre-acknowledged state that prevents redelivery. The operator's dashboard reads from this buffer. When satisfied, a drain_buffer() call injects any operator annotations and publishes to the orchestrator.
The buffer supports the full operator workflow: manual release and reject, pause and resume, adaptive hold (based on response divergence), auto-approve timeout for low-risk automated flows, and explicit stop/unstop for agents under investigation.
ResponseBuffer ships with 150+ unit tests covering all state transitions.
2. Score-Based Agent Monitoring and Auto-Flagging
AgentStatusSnapshot gains 10 new fields in v0.5.1. The additions that matter most for fleet operators are the scoring fields: recent_scores, mean_score, and score_std_dev. These are populated via worker subscription to round_summary NATS events — agents maintain rolling peer evaluation scores automatically.
Score-based auto-flagging runs continuously: agents with a mean score below 4.0 or a standard deviation above 3.0 are automatically flagged for operator attention with a machine-readable flag_reason. Flagged agents remain in the deliberation pool — the system surfaces the signal, the operator decides.
Orchestrator-side agent filtering operates on the same score data. min_mean_score, max_divergence, and grace_rounds configuration controls allow automatic exclusion of underperforming agents. Quorum-2 protection ensures at least two agents remain active regardless of filter outcomes. The filter is non-sticky: once an agent's scores recover, it re-enters the pool automatically.
3. ConfigPatch and Runtime Control
ConfigPatch enables validated runtime updates to agent configuration — temperature, frequency/presence penalties, persona, feedback style, iteration count, and retry budget — applied live without restarting agents or the orchestrator. Changes go through range validation before propagation. The AgentControlPlane trait defines the full async interface for HITL operations at the worker level.
The dashboard Config tab exposes all patch parameters as sliders with debounced auto-save. Operators tuning agent behavior mid-deliberation no longer need to touch configuration files or restart containers.
4. SLA Phase Floor
BudgetManager now enforces a minimum phase timeout derived from each agent's declared response_sla_secs. Agents are never allocated less time than their stated SLA. When budget consumption exceeds 80%, a feasibility warning surfaces in the dashboard budget card before phase planning continues.
This closes a class of bugs where tight global budget constraints could silently under-provision fast-cycling agents, producing spurious timeouts that degraded convergence quality without obvious diagnostic signal.
5. Infrastructure: Embedded NATS and Multi-Arch Docker
v0.5.1 makes the full NSED stack deployable in a single command:
docker run ghcr.io/peeramid-labs/nsed:v0.5.1
The orchestrator image bundles a static nats-server v2.12.4 binary with SHA256 digest pinned and verified at build time. No external NATS deployment required. A dual health check probes both the orchestrator API and the NATS TCP port. Configurable via NATS_STORE_DIR, NATS_READY_RETRIES, and NATS_READY_SLEEP.
Images publish for both linux/amd64 and linux/arm64 via Buildx and QEMU. A separate minimal agent image — ghcr.io/peeramid-labs/nsed-agent:v0.5.1 — is published alongside the orchestrator for worker-only deployments.
A .dockerignore prevents local credential files from reaching image layers.
6. nsed-orchestrator init: Zero-to-Running in Minutes
The nsed-orchestrator init wizard handles provider discovery, model selection, agent assignment, and output generation in a single interactive session. It discovers local Ollama instances automatically, walks through provider configuration (Together AI, OpenRouter, OpenAI, Ollama, any OpenAI-compatible endpoint, or Simulated), and uses a model-first assignment flow where integration-tested models sort to the top with a visual confirmation marker.

Output: a complete docker-compose.yml, .env, and .gitignore ready for docker compose up.
Twenty-two agent personas from config/default.yml are available grouped by ensemble — General, Security, Quant, Supply, and Legal. Together AI model discovery uses a dual-parse strategy with type-based filtering. A shared nsed-cli-common crate powers both nsed-orchestrator init and the worker-only nsed-agent init.
7. Structured Evaluation and LLM Resilience
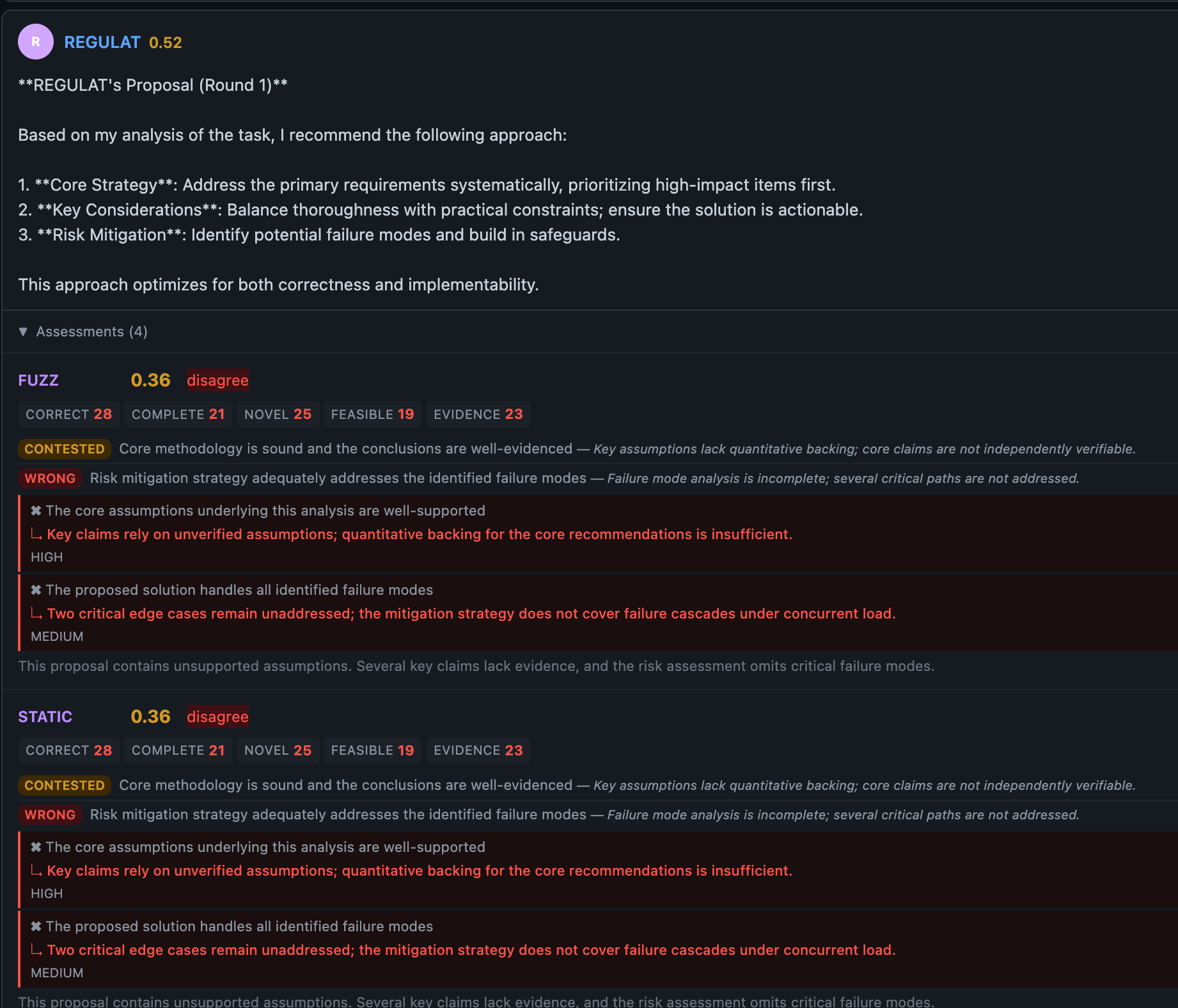
Evaluators now produce typed claim-level assessments via new SDK types: ClaimVerdict, Stance, Confidence, ClaimAssessment, DisagreementPoint, and CategoryScores. Proposers receive machine-readable feedback on exactly which claims were disputed and why, enabling targeted refinement in subsequent rounds rather than full regeneration.
LLM output parsing has been hardened with 11+ serde alias mappings for evaluator_position and 5 for proposal_claims, covering known hallucinated field names from GPT-OSS, MiniMax, and Mistral. Multi-stage repair handles malformed outputs before surfacing an error. Automatic parse error dumps to a failures/ directory (configurable: on, full with system prompt, off) give operators diagnostic artifacts without manual instrumentation.
Transport-level resilience covers connection resets, EOF, broken pipe, and timeout — all auto-retry with exponential backoff. A 402 Payment Required handler manages transient billing interruptions with backoff up to half the agent's remaining SLA budget.
8. NATS JWT Cryptographic Agent Identity
Each agent receives a scoped NATS User JWT signed by the orchestrator via challenge-response issuance. Agents prove Ed25519 NKey ownership before credentials are issued. The NATS URL itself is protected behind a SHA-256 hash commitment, preventing credential reuse against unauthorized brokers.
Agents need only two environment variables to bootstrap: NSED_ORCHESTRATOR_URL and NSED_BEARER_TOKEN. The OrchestratorRegistry exposes a REST API for multi-orchestrator agent connectivity — a single agent process can participate in deliberations across multiple orchestrators simultaneously.
The scoped JWT architecture is also the foundation for the blind orchestration model shipping in v0.6.0: an orchestrator that can coordinate agent deliberations without being able to read the payload content. Operators retain full oversight of the process; the infrastructure itself cannot access the underlying data. For organizations in legal, financial, or healthcare verticals where the deliberation content is privileged or regulated, this separation is the difference between a usable deployment and a non-starter.
Testing Coverage
v0.5.1 ships with 300+ new test functions. Coverage additions by area:
- ResponseBuffer: 150+ unit tests covering all state transitions
- CLI init: 7,400+ lines of integration tests across wizard flows
- Agent filter: 2,500+ lines — quorum-2 protection, grace rounds, divergence filtering
- SLA phase floor: 900+ lines
- HITL REST endpoints: 101 test functions across all 16+ endpoints
- Structured evaluation serde: 11 regression tests for alias coverage
- Full e2e lifecycle, heartbeat, worker coverage across all three crates
Getting Started
Orchestrator + embedded NATS (single container):
docker run ghcr.io/peeramid-labs/nsed:v0.5.1
Agent image (worker-only):
docker run ghcr.io/peeramid-labs/nsed-agent:v0.5.1
Interactive setup wizard:
nsed-orchestrator init
The wizard generates a complete docker-compose.yml + .env. From there, docker compose up starts a full multi-agent deliberation stack.
What's Coming in v0.6.0
v0.6.0 ships the cryptographic compliance infrastructure that regulated industry deployments require.
If your compliance deadline is August, get in touch now — we'll scope what's needed for your deployment.
The architecture is a dual-crate design: nsed-crypto-core (MIT) for trait definitions, and nsed-crypto (BSL 1.1) for the signing implementations. Signing support covers Ed25519 and secp256k1/EIP-712 for classical deployments, and ML-DSA-65 for post-quantum requirements.
Every lifecycle event receives a cryptographic audit envelope. Human operator injections produce a signed, attributable audit trail. Poseidon BN254 commitment chains link events into tamper-evident sequences. An emergency kill switch satisfies EU AI Act Article 14 comprehension requirements. C2PA output provenance metadata addresses Article 50.
The compliance test suite ships as cargo test --features compliance — 32 tests with explicit regulatory mapping to EU AI Act Art. 12/14/50, C2PA, MAS AIRM, FINRA 2026, and NIST FIPS 204. Enterprise procurement teams evaluating v0.6.0 will have a runnable artifact that maps NSED behavior to specific regulatory obligations.
NSED is source-available under BSL 1.1 (converts to AGPL-3.0 after four years). The Agent SDK and CLI are MIT licensed. Production use above $1M ARR requires a commercial license. Development, testing, research, and organizations under the revenue threshold use NSED freely under the Additional Use Grant.
GitHub · Docker Hub · arXiv 2601.16863
Questions: contact@peeramid.xyz